
// 퇴근후딴짓 님의 강의를 참고하였습니다. //
Dataset :
문제) 보험가입 확률을 다음과 같은 형식의 CSV 파일로 생성하시오.

1. 데이터 불러오기
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
2. EDA
# 크기 확인
train.shape, test.shape
실행 결과 :
((1490, 10), (497, 9))# 샘플 확인
train.head()
→ TravelInsurance 컬럼이 Target으로 사용될 컬럼이다.
# 타입 확인
train.info()
실행 결과 :
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1490 entries, 0 to 1489
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 1490 non-null int64
1 Age 1490 non-null int64
2 Employment Type 1490 non-null object
3 GraduateOrNot 1490 non-null object
4 AnnualIncome 1490 non-null int64
5 FamilyMembers 1490 non-null int64
6 ChronicDiseases 1490 non-null int64
7 FrequentFlyer 1490 non-null object
8 EverTravelledAbroad 1490 non-null object
9 TravelInsurance 1490 non-null int64
dtypes: int64(6), object(4)
memory usage: 116.5+ KB→ train은 6개의 수치형 변수, 4개의 명목형 변수로 이루어져있다.
# 결측치 확인 train
train.isnull().sum()
실행 결과 :
Unnamed: 0 0
Age 0
Employment Type 0
GraduateOrNot 0
AnnualIncome 0
FamilyMembers 0
ChronicDiseases 0
FrequentFlyer 0
EverTravelledAbroad 0
TravelInsurance 0
dtype: int64→ train의 결측치는 없다.
# 결측치 확인 test
test.isnull().sum()
실행 결과 :
Unnamed: 0 0
Age 0
Employment Type 0
GraduateOrNot 0
AnnualIncome 0
FamilyMembers 0
ChronicDiseases 0
FrequentFlyer 0
EverTravelledAbroad 0
dtype: int64→ test의 결측치는 없다.
# 기초 통계 획인
train.describe()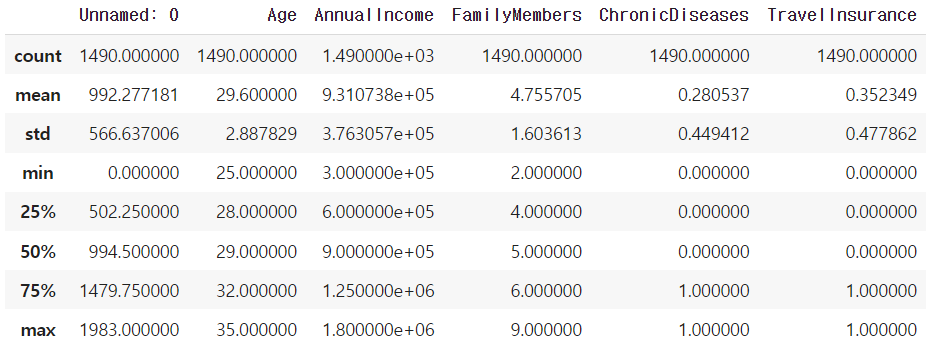
→ 나이(Age)가 25~35세 사이이다. 나이 분포가 다양하다면 10대, 20대와 같이 범위로 나타내는 방법도 있다.
# 기초 통계 획인 object
train.describe(include='object')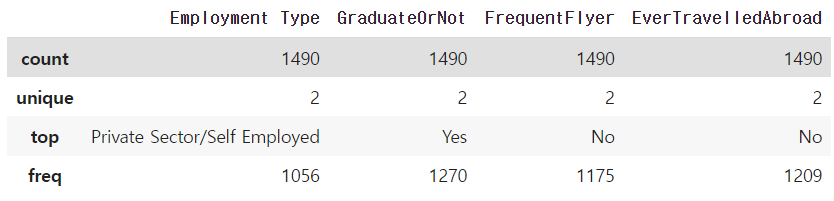
→ 명목형 변수의 카테고리가 각각 2개로 이루어져있다.
# 타겟(레이블)
train['TravelInsurance'].value_counts()
실행 결과 :
0 965
1 525
Name: TravelInsurance, dtype: int64→ Target을 value_counts()로 확인 시 0(보험 가입 o) 965개, 1(보험 가입 x) 525개로 보험가입자가 더 많다.
3. 데이터 전처리 및 피처엔지니어링
# 수치형 데이터와 범주형 데이터 분리
n_train = train.select_dtypes(exclude='object').copy()
c_train = train.select_dtypes(include='object').copy()
n_test = test.select_dtypes(exclude='object').copy()
c_test = test.select_dtypes(include='object').copy()→ 스케일링과 원-핫 인코딩을 진행하기 위해 수치형 데이터와 범주형 데이터로 분리한다.
# 수치형 변수
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
cols = ['Age', 'AnnualIncome', 'FamilyMembers', 'ChronicDiseases']
display(n_train.head())
n_train[cols] = scaler.fit_transform(n_train[cols])
n_test[cols] = scaler.transform(n_test[cols])
n_train.head()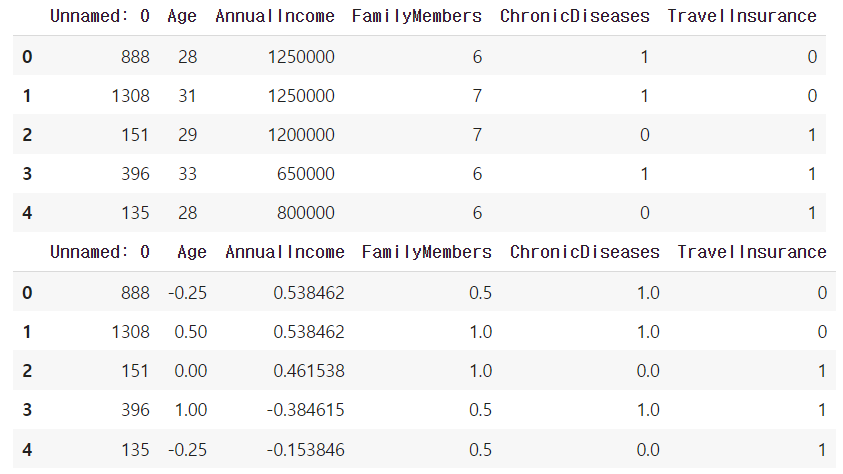
→ 수치형 변수는 RobustScaler를 사용해 Unnamed 컬럼을 제외한 4개의 컬럼을 스케일링 진행한다.
(RobustScaler 사용 이유는 다른 스케일링 방식보다 이상치에 덜 민감하기 때문이다.)
# 범주형 변수
display(c_train.head())
c_train = pd.get_dummies(c_train)
c_test = pd.get_dummies(c_test)
c_train.head()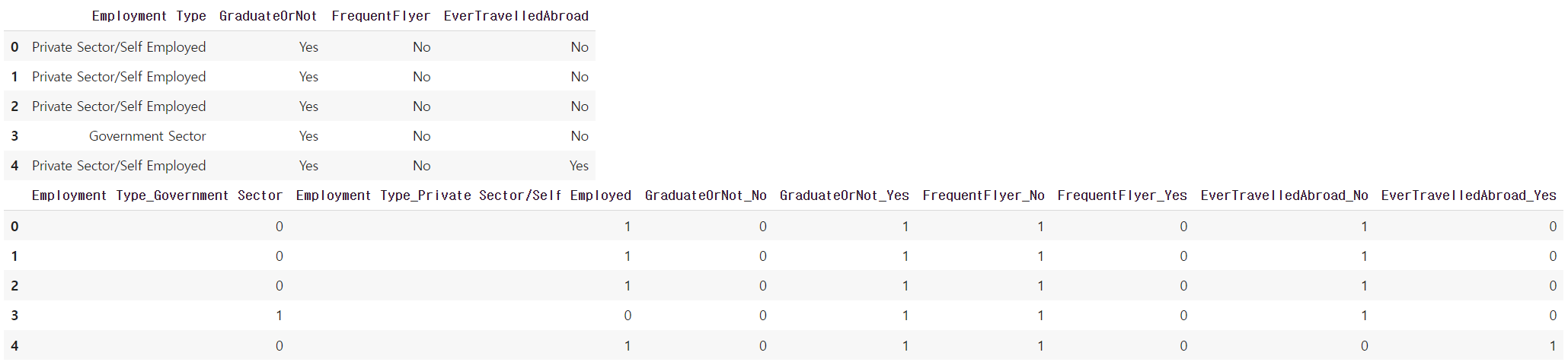
→ 범주형 변수는 카테고리가 Yes, No 2개로 이루어져있어 원-핫 인코딩을 진행하였다.
# 분리한 데이터 다시 합침
train = pd.concat([n_train, c_train], axis=1)
test = pd.concat([n_test, c_test], axis=1)
print(train.shape, test.shape)
train.head()
실행 결과 : (1490, 14) (497, 13)
→ 스케일링과 원-핫 인코딩 진행 후 다시 데이터를 합쳐준다.
4. 검증데이터 분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(train.drop('TravelInsurance', axis=1),
train['TravelInsurance'],
test_size=0.1,
random_state=1204)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shape
실행 결과 :
((1341, 13), (149, 13), (1341,), (149,))→ 모델링을 하기 위해 훈련용 데이터와 검증용 데이터로 분리한다.
5. 모델링
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=400, max_depth=9, random_state=1204)
rf.fit(X_tr, y_tr)
pred = rf.predict_proba(X_val)[:,1]from sklearn.metrics import roc_auc_score
roc_auc_score(y_val, pred)
실행 결과 :
0.8277551020408163→ 랜덤포레스트 모델로 훈련 후 검증용으로 예측 및 평가하면 예측률이 0.82로 측정된다.
6. 예측
# test 예측
pred = rf.predict_proba(test)[:,1]→ 모델링이 끝난 후 test 데이터를 예측한다.
# csv 파일 생성 (예시와 다른 형태)
pd.DataFrame({'index':test.index,'y_pred':pred}).to_csv('0000.csv', index=False)→ 문제에서 제시된 형태로 index 열과 y_pred 열로 데이터 프레임을 만든 후 csv 파일을 생성한다.
# 확인
pd.read_csv("0000.csv")
→ csv 생성 후 pd.read_csv를 통해 제대로 생성되었는지 재확인을 해준다.
7. 채점
y_test = pd.read_csv("y_test.csv")
roc_auc_score(y_test, pred)
실행 결과 :
0.7875693000693→ 수험자가 알 수 없는 부분이지만 y_test 파일로 평가 진행 시 0.78의 예측률을 확인 할 수 있다.
'빅데이터분석기사 > 작업형2' 카테고리의 다른 글
| [작업형2] 심장마비 확률 높은 사람 구하기(분류 / 튜닝) (0) | 2023.06.17 |
|---|---|
| [작업형2] 에어비앤비 가격 예측하기(회귀) (0) | 2023.06.17 |
| [작업형2] 신용카드 서비스를 떠나는 고객 확률 구하기(분류) (0) | 2023.06.17 |
| [작업형2] 제품 배송 시간에 맞춰 배송되었는지 예측하기(분류) (0) | 2023.06.15 |
| [작업형2] 고객의 성별이 남자일 확률 구하기(분류) (1) | 2023.06.15 |