
// 퇴근후딴짓 님의 강의를 참고하였습니다. //
Dataset :
문제) 백화점 고객의 1년간 구매 데이터에서 고객의 성별 예측값(남자일 확률)을 다음과 같은 형식의 CSV 파일로 생성하시오.

- cust_id : 고객 ID
- gender : 성별 (0: 여자, 1: 남자)
1. 데이터 불러오기
import pandas as pd
X_train = pd.read_csv("X_train.csv", encoding="euc-kr")
y_train = pd.read_csv("y_train.csv")
X_test = pd.read_csv("X_test.csv", encoding="euc-kr")→ 시험환경에서는 encoding="euc-kr"가 없어도 된다.
2. EDA
# 데이터 크기
X_train.shape, y_train.shape, X_test.shape
실행 결과 :
((3500, 10), (3500, 2), (2482, 10))
# 데이터 샘플 X_train
X_train.head(3)
→ X_train은 cust_id, 총구매액, 최대구매액, 환불금액 등 10개의 열로 이루어져있다.
# 데이터 샘플 y_train
y_train.head(3)
→ y_train은 cust_id와 gender 2개의 열로 이루어져있다.
# 데이터 샘플 X_test
X_test.head(3)
→ X_test는 X_train과 동일하게 10개의 열로 이루어져있다.
# [Tip] 컬럼이 다보이지 않을 때
pd.set_option('display.max_columns', None)→ 시험환경에서 컬럼이 전부 보이지 않을때 사용
# 결측치 확인 train
X_train.isnull().sum()
실행 결과 :
cust_id 0
총구매액 0
최대구매액 0
환불금액 2295
주구매상품 0
주구매지점 0
내점일수 0
내점당구매건수 0
주말방문비율 0
구매주기 0
dtype: int64# 결측치 확인 test
X_test.isnull().sum()
실행 결과 :
cust_id 0
총구매액 0
최대구매액 0
환불금액 1611
주구매상품 0
주구매지점 0
내점일수 0
내점당구매건수 0
주말방문비율 0
구매주기 0
dtype: int64→ X_train과 X_test에서 환불금액에 결측치가 있는 것을 확인
# 기초 통계
X_train.describe()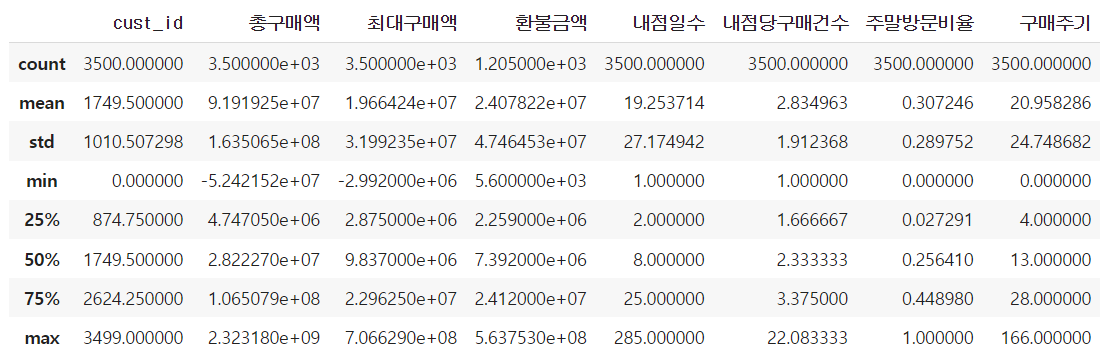
# [Tip] 지수표현식(과학적표기법) 사용 X
pd.options.display.float_format = '{:.2f}'.format
X_train.describe()
→ e+03과 같은 지수표현식을 사용하고 싶지 않을때 사용한다.
→ '{: .2f}'에서 숫자를 변경하여 소수점 자리 설정이 가능하다.
# 기초 통계 object
X_train.describe(include='object')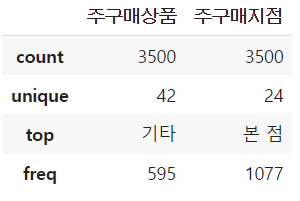
→ X_train의 명목형 변수는 주구매상품, 주구매지점 2가지 이다.
→ 주구매상품이 42개의 고유값으로 이루어져있다.
# 기초 통계 object (x_test)
X_test.describe(include='object')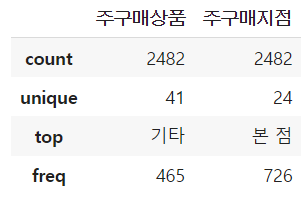
→ X_test의 명목형 변수 역시 주구매상품, 주구매지점 2가지 이다.
→ 주구매상품이 41개의 고유값으로 이루어져있다.
→ count : 행의 개수
→ unique : 상품 종류의 수 (고유값)
→ top : 제일 많은 상품 종류
→ freq : 제일 많은 상품 빈도수
# 고유값 (train)
X_train['주구매상품'].unique()
실행 결과 :
array(['기타', '스포츠', '남성 캐주얼', '보석', '디자이너', '시티웨어', '명품', '농산물', '화장품',
'골프', '구두', '가공식품', '수산품', '아동', '차/커피', '캐주얼', '섬유잡화', '육류',
'축산가공', '젓갈/반찬', '액세서리', '피혁잡화', '일용잡화', '주방가전', '주방용품', '건강식품',
'가구', '주류', '모피/피혁', '남성 트랜디', '셔츠', '남성정장', '생활잡화', '트래디셔널',
'란제리/내의', '커리어', '침구/수예', '대형가전', '통신/컴퓨터', '식기', '소형가전', '악기'],
dtype=object)# 고유값 (test)
X_test['주구매상품'].unique()
실행 결과 :
array(['골프', '농산물', '가공식품', '주방용품', '수산품', '화장품', '기타', '스포츠', '디자이너',
'시티웨어', '구두', '캐주얼', '명품', '건강식품', '남성정장', '커리어', '남성 캐주얼', '축산가공',
'식기', '피혁잡화', '모피/피혁', '섬유잡화', '트래디셔널', '차/커피', '육류', '가구', '아동',
'셔츠', '액세서리', '젓갈/반찬', '대형가전', '일용잡화', '통신/컴퓨터', '생활잡화', '주방가전',
'란제리/내의', '남성 트랜디', '보석', '주류', '침구/수예', '악기'], dtype=object)→ .unique() 함수로 해당 열의 고유값을 얻을 수 있다.
# [Tip] set 타입으로 변경하면 비교 가능함
a = set(X_train['주구매상품'].unique())
b = set(X_test['주구매상품'].unique())
print(a - b)
print(a.difference(b))
실행 결과 :
{'소형가전'}
{'소형가전'}→ 위에서 보았듯 X_train의 주구매상품은 42개, X_test의 주구매상품은 41개로 이루어져있다.
→ set 타입으로 변경 후 두 변수를 빼거나, differnce() 함수를 사용하면 1개의 주구매상품이 무엇인지 쉽게 알 수 있다.
# target(label) 값 확인
y_train['gender'].value_counts()
실행 결과 :
0 2184
1 1316
Name: gender, dtype: int64→ y_train 성별 컬럼은 0(여자) 2184개, 1(남자) 1316개의 행으로 이루어져있다.
3. 데이터 전처리
# 결측치처리
X_train = X_train.fillna(0) # 환불금액 0값으로 채움
X_test = X_test.fillna(0)→ X_train과 X_test의 결측치(환불금액)을 0으로 채운다.
# id 삭제함 (단 test의 id값은 csv파일을 생성할 때 필요함으로 옮겨 놓음)
X_train = X_train.drop(['cust_id'], axis=1)
cust_id = X_test.pop('cust_id')→ X_train에서 필요없는 cust_id 열을 삭제한다.
→ cust_id 열은 csv파일 제출시 필요하기 때문에 cust_id 변수에 따로 저장해 둔다.
→ pop()은 해당 컬럼을 꺼내 변수에 값을 넘겨준 다음 X_test에서 cust_id 열을 삭제해준다.
4. 피처엔지니어링
# 라벨 인코더
from sklearn.preprocessing import LabelEncoder
cols = ['주구매상품', '주구매지점']
for col in cols:
le = LabelEncoder()
X_train[col] = le.fit_transform(X_train[col])
X_test[col] = le.transform(X_test[col])
X_train.head()
→ 주구매상품과 주구매지점 같은 [명목형 변수]를 LabelEncoder 작업을 한다.
# MinMaxScaler 수치형
from sklearn.preprocessing import MinMaxScaler
cols = ['총구매액', '최대구매액', '환불금액', '내점일수', '내점당구매건수', '주말방문비율', '구매주기']
scaler = MinMaxScaler()
X_train[cols] = scaler.fit_transform(X_train[cols])
X_test[cols] = scaler.fit_transform(X_test[cols])
X_train.head()
→ 총구매액, 최대구매액 등의 [수치형 변수]를 MinMaxScaler 작업을 한다.
5. 데이터 분리
# 검증 데이터 분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(X_train,
y_train['gender'],
test_size = 0.2,
random_state = 2022
)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shape
실행 결과 :
((2800, 9), (700, 9), (2800,), (700,))→ X_train, y_train 데이터를 훈련용과 검증용 데이터로 분리한다.
→ test_size : val(검증용 데이터)의 비율 설정
→ random_state : 분리 시 마다 일정하게 하기 위한 설정
6. 모델링
# 모델링 & 하이퍼파라미터 튜닝 & 앙상블
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=2022)
model.fit(X_tr, y_tr)
pred = model.predict_proba(X_val)→ 랜덤포레스트 모델을 사용해 훈련용 데이터를 학습시키고 검증용 데이터로 예측을 실시한다.
→ random_state를 설정하지 않으면 훈련할때마다 예측 결과가 다르게 나온다.
→ predict_proba 함수는 예측 확률을 나타낸다.
# 예측 결과 확인
pred
실행 결과 :
array([[0.66, 0.34],
[0.37, 0.63],
[0.89, 0.11],
...,
[0.61, 0.39],
[0.55, 0.45],
[0.45, 0.55]])→ 예측 결과에서 왼쪽값이 0(여자)일 확률, 오른쪽값이 1(남자)일 확률을 나타낸다.
7. 평가(self)
# 검증 데이터 셋으로 평가
from sklearn.metrics import roc_auc_score
roc_auc_score(y_val, pred[:,1])
실행 결과 :
0.6098414179104478→ roc_auc_score를 통해 검증 데이터(y_val)로 평가시 60.98%의 예측률을 나타낸다.
→ pred[:, 0] : 여자일 확률 / pred[:, 1] : 남자일 확률
8. 예측 및 제출
# test 데이터 예측
pred = model.predict_proba(X_test)
pred
실행 결과 :
array([[0.47, 0.53],
[0.75, 0.25],
[0.77, 0.23],
...,
[0.57, 0.43],
[0.5 , 0.5 ],
[0.54, 0.46]])→ 테스트 데이터(X_test)로 예측을 실시한다.
# 데이터 프레임 만들기
submit = pd.DataFrame(
{
'cust_id' : cust_id,
'gender' : pred[:,1]
}
)→ 데이터프레임을 만들어 pop()을 통해 빼두었던 cuit_id와 남자일 확률을 예측한 pred[:,1] 값을 담는다.
# 샘플 데이터 확인
submit.head()
# csv 생성
submit.to_csv("수험번호.csv", index=False)→ .to_csv() 함수를 사용해 제출용 csv 파일을 생성한다.
→ index = False를 하지 않을시 인덱스 열이 자동으로 생성되어 문제에서 제시한 cust_id, gender 2개의 열로 되지 않는다.
9. 제대로 제출 되었는지 확인
pd.read_csv("수험번호.csv")
→ 생성한 csv 파일을 불러와 제대로 제출 되었는지 확인한다.
'빅데이터분석기사 > 작업형2' 카테고리의 다른 글
| [작업형2] 심장마비 확률 높은 사람 구하기(분류 / 튜닝) (0) | 2023.06.17 |
|---|---|
| [작업형2] 에어비앤비 가격 예측하기(회귀) (0) | 2023.06.17 |
| [작업형2] 신용카드 서비스를 떠나는 고객 확률 구하기(분류) (0) | 2023.06.17 |
| [작업형2] 보험가입 확률 구하기(분류) (1) | 2023.06.17 |
| [작업형2] 제품 배송 시간에 맞춰 배송되었는지 예측하기(분류) (0) | 2023.06.15 |