
// 퇴근후딴짓 님의 강의를 참고하였습니다. //
Dataset :
test.csv
0.07MB
train.csv
0.18MB
y.csv
0.01MB
문제) 중고 자동차 가격을 예측하여 다음과 같은 형식으로 제출하시오.
- 자동차 가격을 예측해주세요!
- 예측할 값(y): price
- 평가: RMSE (Root Mean Squared Error)
- data: train.csv, test.csv
1. EDA
# 데이터 불러오기
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")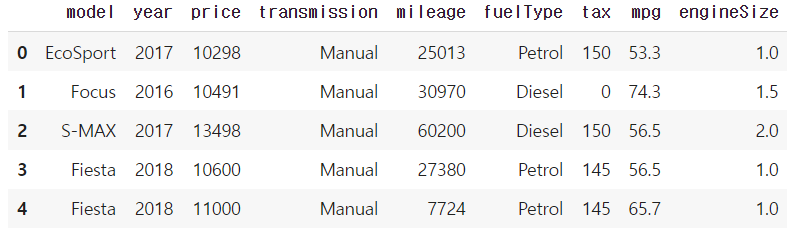
train.info()
실행 결과 :
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3759 entries, 0 to 3758
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 model 3759 non-null object
1 year 3759 non-null int64
2 price 3759 non-null int64
3 transmission 3759 non-null object
4 mileage 3759 non-null int64
5 fuelType 3759 non-null object
6 tax 3759 non-null int64
7 mpg 3759 non-null float64
8 engineSize 3759 non-null float64
dtypes: float64(2), int64(4), object(3)→ 6개의 수치형 변수, 3개의 명목형 변수로 이루어져있다.
train.isnull().sum()
실행 결과 :
model 0
year 0
price 0
transmission 0
mileage 0
fuelType 0
tax 0
mpg 0
engineSize 0
dtype: int64test.isnull().sum()
실행 결과 :
model 0
year 0
transmission 0
mileage 0
fuelType 0
tax 0
mpg 0
engineSize 0
dtype: int64→ train, test 데이터 모두 결측치는 없다.
y_train = train.pop("price")→ 가격 예측에 사용될 'price' 컬럼은 y_train 변수에 따로 담아두고 train 데이터에서 삭제한다.
2. 수치형 활용
cols = ['year', 'mileage', 'tax', 'mpg', 'engineSize']
train = train[cols]
test = test[cols]→ train, test 데이터에서 수치형 변수들만 선택한다.
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(train, y_train, test_size=0.2, random_state=2022)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shapefrom sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_tr, y_tr)
pred = rf.predict(X_val)→ 랜덤포레스트 회귀 모형으로 훈련 및 예측을 실시한다.
from sklearn.metrics import mean_squared_error
def rmse(y_true, y_pred):
return mean_squared_error(y_true, y_pred)**0.5→ 사이킷런에서 rmse는 제공하고 있지 않아 함수로 rmse 계산 방식을 만들어준다.
rmse(y_val, pred)
실행 결과 :
1565.0567336921324→ 검증 데이터로 평가 시 1565가 나온다.
3. 수치형 + 범주형 활용
train = pd.get_dummies(train)
test = pd.get_dummies(test)→ train, test 데이터를 get_dummies 함수를 사용해 원핫 인코딩을 진행한다.
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(train, y_train, test_size=0.2, random_state=2022)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shapefrom sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_tr, y_tr)
pred = rf.predict(X_val)
rmse(y_val, pred)→ 원핫인코딩 진행 후 평가 진행시 rmse는 1305가 나온다.
→ rmse는 오차에 기반하기 때문에 숫자가 낮을수록 좋다. 즉, 원핫 인코딩 진행 후 더 좋은 성능이 나온 것이다.
4. Test 예측
pred = rf.predict(test)
result = pd.DataFrame({
'pred':pred
})
result.to_csv("result.csv", index=False)pd.read_csv('result.csv')→ 문제에서 제시한 형식대로 'pred' 컬럼에 pred값을 넣어 데이터프레임으로 만든 후 제출
'빅데이터분석기사 > 작업형2' 카테고리의 다른 글
| [작업형2] 자동차 시장 세분화(분류) (0) | 2023.06.24 |
|---|---|
| [작업형2] 유방암 예측 모델 만들기(분류) (0) | 2023.06.22 |
| [작업형2] 심장마비 확률 높은 사람 구하기(분류 / 튜닝) (0) | 2023.06.17 |
| [작업형2] 에어비앤비 가격 예측하기(회귀) (0) | 2023.06.17 |
| [작업형2] 신용카드 서비스를 떠나는 고객 확률 구하기(분류) (0) | 2023.06.17 |