
// 퇴근후딴짓 님의 강의를 참고하였습니다. //
Dataset :
문제7)
- index '2001' 데이터(행)의 평균보다 큰 값의 수와
- index '2003' 데이터(행)의 평균보다 작은 값의 수를 더하시오.
# 데이터 생성
import pandas as pd
import random
df = pd.DataFrame()
for i in range(0, 5):
list_box = []
for k in range(0, 200):
ran_num = random.randint(1,200)
list_box.append(ran_num)
df[i+2000] = list_box
df = df.T
df.to_csv("data.csv", index=True)→ 7번 문제에서 사용할 data.csv 파일을 만드는 코드이다.
df = pd.read_csv("data.csv", index_col="Unnamed: 0")
print(df.head(2))
실행 결과 :
0 1 2 3 4 5 6 7 8 9 ... 190 191 192 193 \
2000 137 74 114 140 80 150 16 133 178 181 ... 124 94 118 12
2001 176 87 64 110 128 16 8 4 123 87 ... 59 22 3 108
194 195 196 197 198 199
2000 50 191 137 174 56 128
2001 17 104 101 161 156 43m2001 = df.loc[2001].mean()
cond = df.loc[2001] > m2001
r1 = sum(cond)
print(r1)
m2003 = df.loc[2003].mean()
cond = df.loc[2003] < m2003
r2 = sum(cond)
print(r2)
print(r1+r2)
실행 결과 :
100
102
202→ 2001년도 평균을 구해 m2001 변수에 담은 후 평균보다 큰 개수를 r1에 담는다. 개수는 100개이다.
→ 2003년도 평균을 구해 m2003 변수에 담은 후 평균보다 작은 개수를 r2에 담는다. 개수는 102개이다.
→ 두 개수를 합하면 202개가 나오게 된다.
문제8)
- 결측 값을 가진 데이터는 바로 뒤에 있는 값으로 대체한 후 (바로 뒤가 결측값이라면 뒤에 있는 데이터 중 가장 가까운 값)
- city와 f2 컬럼 기준으로 그룹합을 계산한 뒤
- views가 세번째로 큰 city(도시) 이름은?
import pandas as pd
df = pd.read_csv("members.csv")display(df.head(7))
df = df.fillna(method='bfill')
display(df.head(7))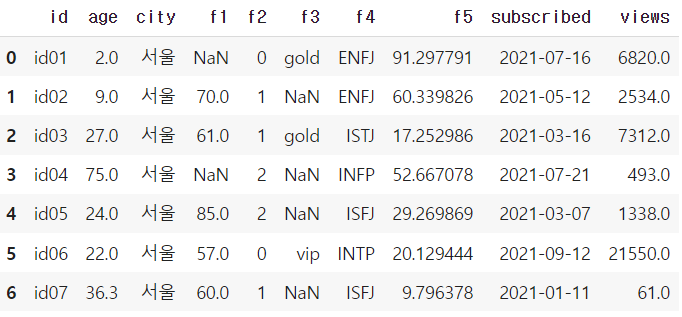
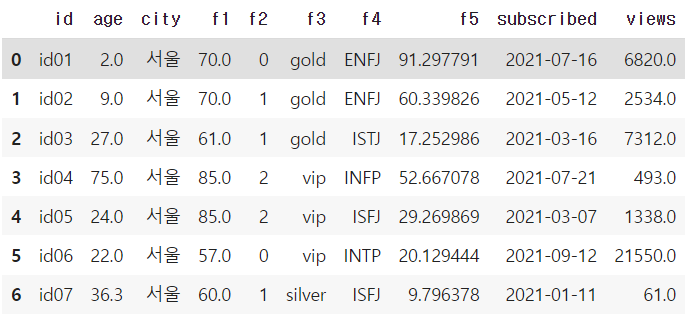
→ 결측치를 바로 뒤에 있는 값으로 대체하는 방법은 fill.na(method='bfill')을 사용하면 된다.
→ 앞에 있는 값으로 대체하는 방법은 fill.na(method='ffill')이다.
df = df.groupby(['city','f2']).sum().reset_index()
df = df.sort_values('views', ascending=False)
print(df.iloc[2,0])
실행 결과 : 대구→ 그룹합을 구하는 방법은 .groupby(['열이름']).sum()을 하면된다. 그 이후 .reset_index()를 하여 인덱스를 초기화한다.
→ 그룹합 이후 3번째로 큰 도시 이름을 구하기 위해 sort_values를 통해 내림차순으로 정렬해준다.
→ 정렬 이후 3번째 도시 이름을 iloc[2,0]을 통해 구하면 대구가 나오게 된다.
문제9)
- 구독(subscribed) 월별로 데이터 개수를 구한 뒤
- 가장 작은 구독 수가 있는 월을 구하시오.
import pandas as pd
df = pd.read_csv("members.csv")df['subscribed'] = pd.to_datetime(df['subscribed'])
df['year'] = df['subscribed'].dt.year
df['month'] = df['subscribed'].dt.month
df['day'] = df['subscribed'].dt.day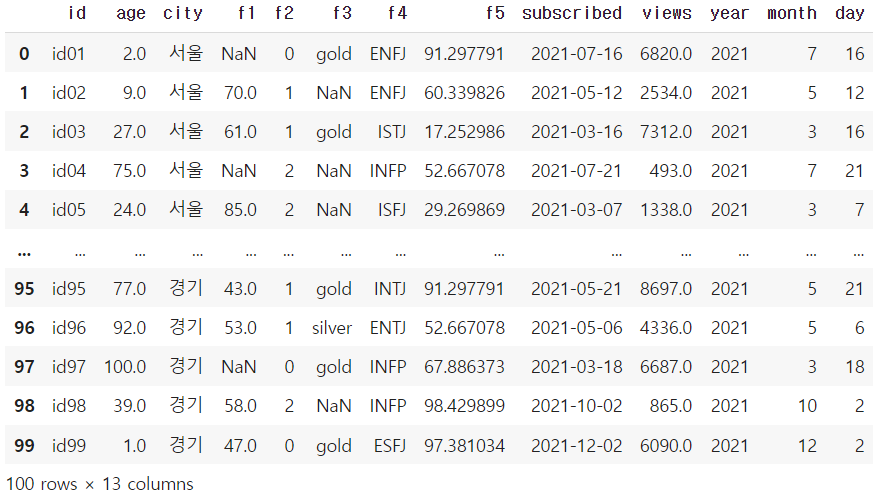
→ object형인 subscribed 열을 pd.to_datatime을 사용해 datatime 형태로 바꾸어 준다.
→ dt.year / dt.month / dt. day를 통해 년 / 월 / 일 열을 간단하게 만들어 줄 수 있다.
df = df.groupby('month').count()
df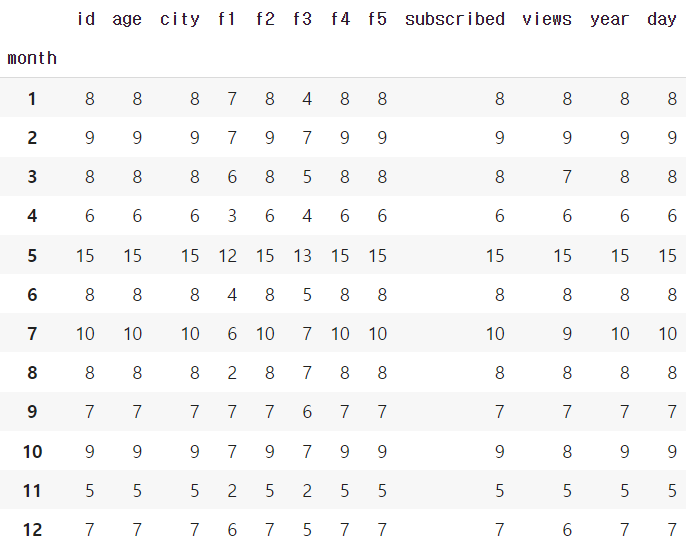
→ groupby('month').count()를 통해 월별 개수를 구해준다.
df.sort_values('subscribed')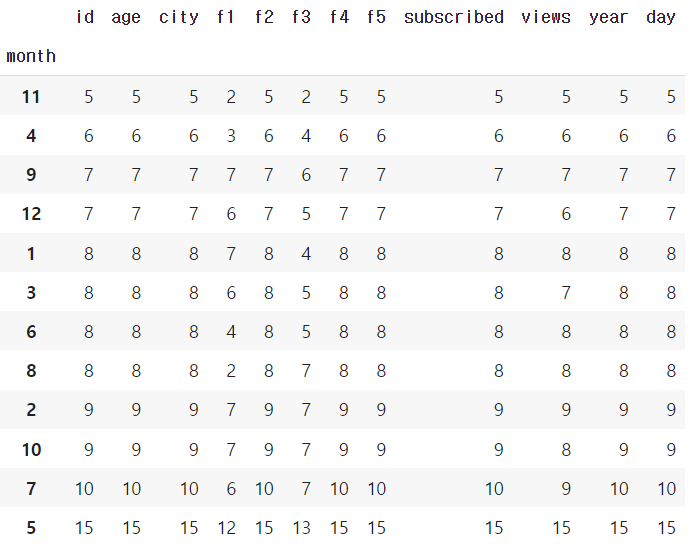
→ 가장 적은 구독자 수의 달을 구하기 위해 sort_values()를 통해 오름차순으로 정렬한다.
df.sort_values('subscribed').index[0]
실행 결과 : 11→ 오름차순 정렬 후 index 0번째를 구하면 11월 달이 나오게 된다.
'빅데이터분석기사 > 작업형1' 카테고리의 다른 글
| [작업형1] 사분위수 / 절대값 / 조건 / datetime 변환 구하기 (0) | 2023.06.24 |
|---|---|
| [작업형1] 평균 / 행(row)별 합 / 고유값 수 구하기 (0) | 2023.06.22 |
| [작업형1] 결측치 대체 / 사분위수 / 표준편차 구하기 (0) | 2023.06.17 |
| [작업형1] 결측치 대체 / 사분위수 구하기 (2) | 2023.06.17 |
| [작업형1] 결측치 / 사분위수 / 데이터 수 구하기 (0) | 2023.06.17 |