
// 퇴근후딴짓 님의 강의를 참고하였습니다. //
Dataset :
1. 데이터 불러오기
import pandas as pd
df = pd.read_csv("members.csv")
df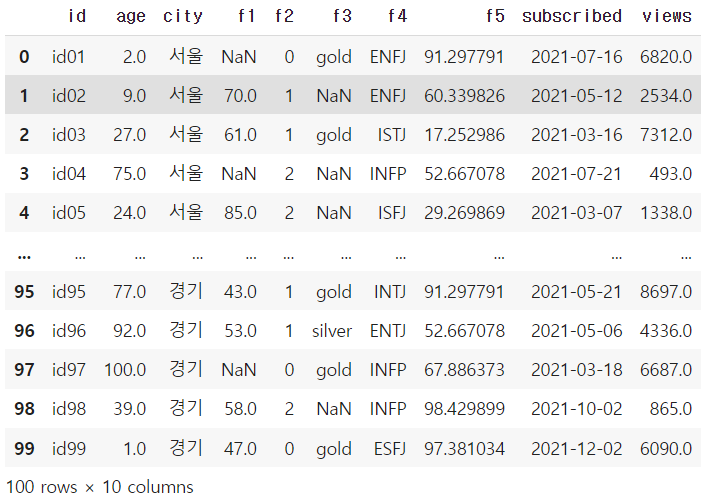
→ 100개의 행과 10개의 열로 이루어져있는 데이터셋이다.
문제1) 결측치 데이터(행)을 제거하고, 앞에서부터 70% 데이터만 활용해, 'f1' 컬럼 1사분위 값을 구하시오.
print(df.isnull().sum())
print(df.shape)
실행 결과 :
id 0
age 0
city 0
f1 31
f2 0
f3 28
f4 0
f5 0
subscribed 0
views 4
dtype: int64
(100, 10)→ df의 결측치 확인 시 f1컬럼에 31개, f1컬럼에 28개, view 컬럼에 4개가 있는 것을 알 수 있다.
df = df.dropna()
print(df.shape)
실행 결과 :
(51, 10)→ dropna()를 통해 결측치를 제거 후 행의 개수를 확인 시 100개에서 51개로 줄어든 것을 알 수 있다.
print(int(len(df)*0.7))
df = df.iloc[:int(len(df)*0.7)]
print(df.shape)
실행 결과 :
35
(35, 10)→ df의 전체 길이 중 70%의 길이를 구한 후 iloc를 통해 df를 70%만 선택한다. 행의 개수가 51개에서 35개로 줄어들었다.
print(df['f1'].quantile(.25))
실행 결과 :
57.0→ quantile(.25)를 사용해 f1컬럼의 1사분위수를 출력시 57.0이 나온다.
문제2) index는 년도임. 2000년 데이터 중 2000년 평균보다 큰 값의 데이터 수를 구하시오. (데이터: 아래 셀 실행)
# 데이터 생성(먼저 실행해 주세요)
import pandas as pd
import random
random.seed(2022)
df = pd.DataFrame()
for i in range(0, 3):
list_box = []
for k in range(0, 200):
ran_num = random.randint(1,200)
list_box.append(ran_num)
df[i+1999] = list_box
df = df.T
df
→ 1999, 2000, 2001 3개의 년도가 행으로 이루어져있고 200개의 열로 이루어진 데이터이다.
# 방법1
m = df.loc[2000].mean()
print(sum(df.loc[2000,:] > m))
실행 결과 :
100→ 첫 번째 방법은 loc를 통해 2000년도 행을 직접 지정해 평균을 m의 변수에 담은 후 sum()으로 개수를 구하는 방법이다.
# 방법2
df = df.T
m = df[2000].mean()
print(sum(df[2000] > m))
실행 결과 :
100
→ 두 번째 방법은 df.T를 사용해 행과 열을 바꿔준 후 2000년도 열의 평균을 구한 후 동일하게 sum()으로 개수를 구하는 방법이 있다.
문제3) 결측치가 제일 큰 값의 컬럼명을 구하시오.
import pandas as pd
df = pd.read_csv("members.csv")# 방법1
df = df.isnull().sum()
df
실행 결과 :
id 0
age 0
city 0
f1 31
f2 0
f3 28
f4 0
f5 0
subscribed 0
views 4
dtype: int64→ 결측치 확인 시 f1컬럼에 31개, f3컬럼에 28개, views컬럼에 4개가 있는 것을 알 수 있다.
df = df.sort_values(ascending=False)
df
실행 결과 :
f1 31
f3 28
views 4
id 0
age 0
city 0
f2 0
f4 0
f5 0
subscribed 0
dtype: int64→ sort_values(ascending=False)를 사용해 결측치 개수를 내림차순으로 정렬 해준다.
print(df.index[0])
실행 결과 :
'f1'→ 결측치가 제일 많은 컬럼은 f1이며 인덱스는 0이므로 df.index[0]을 통해 실행 결과 f1컬럼이 나온다.
# 방법2
df = df.isnull().sum()
df = df.reset_index()
print(df.loc[3, 'index'])
실행 결과 :
'f1'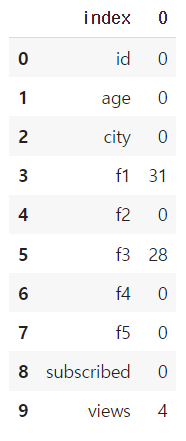
→ 결측치를 구한 후 reset_index()를 사용해 인덱스를 생성해준다.
→ 그 이후 loc를 사용해 결측치가 제일 많은 f1컬럼의 인덱스3과 index열을 선택 후 실행 결과 f1컬럼이 나오게 된다.
'빅데이터분석기사 > 작업형1' 카테고리의 다른 글
| [작업형1] 평균 / 그룹합 / datetime 변환 구하기 (0) | 2023.06.17 |
|---|---|
| [작업형1] 결측치 대체 / 사분위수 / 표준편차 구하기 (0) | 2023.06.17 |
| [작업형1] 결측치 대체 / 사분위수 구하기 (2) | 2023.06.17 |
| [작업형1] 대체 및 평균값 / 표준편차 / 이상치 구하기 (0) | 2023.06.15 |
| [작업형1] 레코드(row) 수 구하기 (0) | 2023.06.15 |