
// 퇴근후딴짓 님의 강의를 참고하였습니다. //
Dataset :
문제1) age 컬럼의 3사분위수와 1사분위수의 차를 절대값으로 구하고, 소수점 버려서, 정수로 출력하시오.
import pandas as pd
df = pd.read_csv("basic1.csv")
df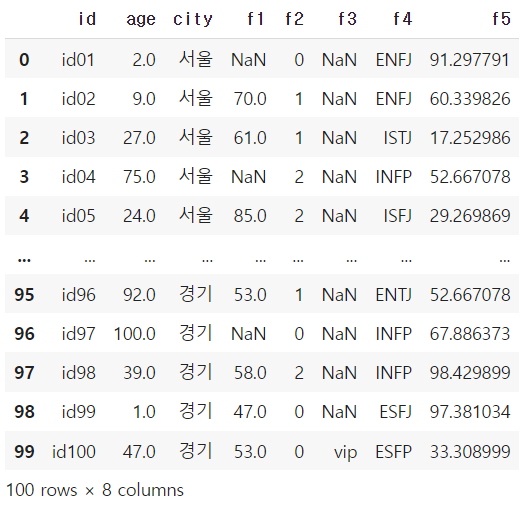
result = abs(df['age'].quantile(0.25) - df['age'].quantile(0.75))
print(int(result))
실행 결과 :
50→ quantile() 함수를 사용해 3분위수와 1분위수를 구한 후 abs() 함수를 사용해 절대값을 씌워준다.
→ 정수로 출력하기 위해 int() 함수를 사용해 출력하면 50이 나온다.
문제2) (loves반응+wows반응)/(reactions반응) 비율이 0.4보다 크고 0.5보다 작으면서, status_type=='video'인 데이터의 갯수를 구하시오.
import pandas as pd
df = pd.read_csv("fb.csv")
df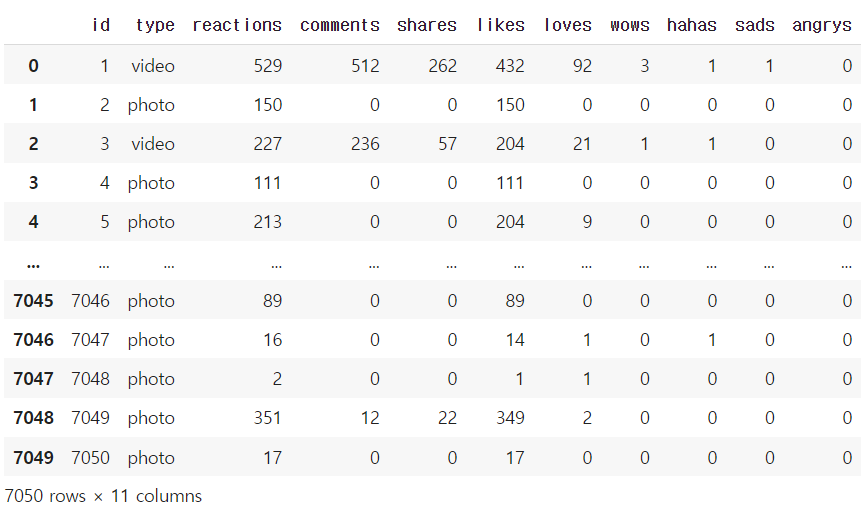
cond1 = (df['loves'] + df['wows'])/ df['reactions'] > 0.4
cond2 = (df['loves'] + df['wows'])/ df['reactions'] < 0.5
cond3 = df['type'] == 'video'
print(len(df[cond1 & cond2 & cond3]))
실행 결과 :
90→ 비율이 0.4보다 큰 조건1 / 비율이 0.5보다 작은 조건2 / 'type' 컬럼이 'video'인 조건3 세 가지를 만든다.
→ 조건 세 가지를 모두 만족하는 개수를 len()함수를 사용하여 출력하면 90개이다.
문제3) date_added가 2018년 1월 이면서 country가 United Kingdom 단독 제작인 데이터의 갯수를 구하시오.
import pandas as pd
df = pd.read_csv("nf.csv")
df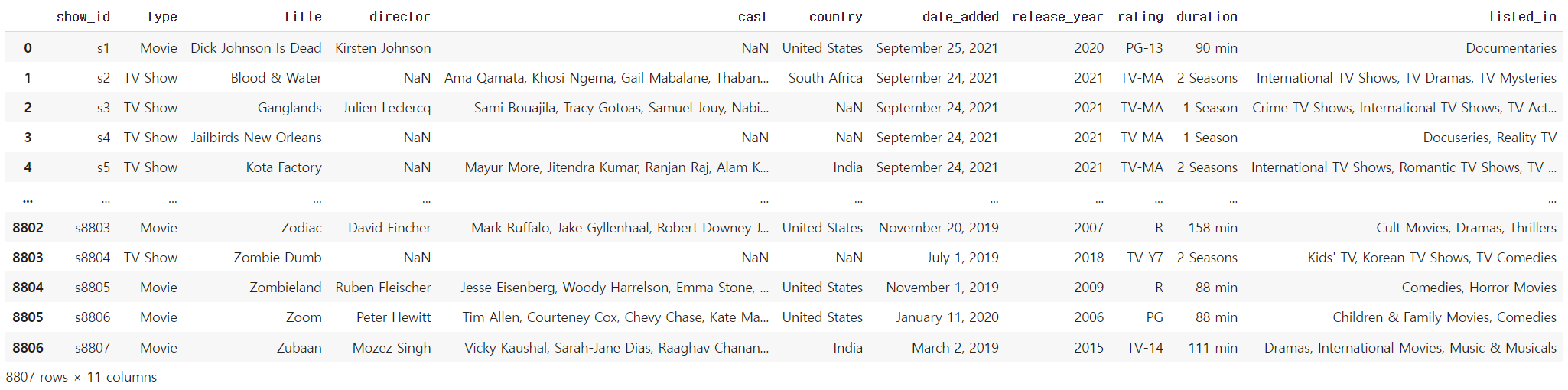
# 풀이1
cond1 = df['country'] == "United Kingdom"
df['date_added'] = pd.to_datetime(df['date_added'])
df['year'] = df['date_added'].dt.year
df['month'] = df['date_added'].dt.month
cond2 = df['year'] == 2018
cond3 = df['month'] == 1
print(len(df[cond1 & cond2 & cond3]))
실행 결과 :
6→ 'object'형인 'country' 컬럼을 pd.to_datetime() 함수를 사용해 변환해준다.
→ dt.year / dt.month 함수를 사용해 년 / 월 컬럼을 만들어준다.
→ 'country' 컬럼이 'United Kingdom"인 조건1을 만든다.
→ 년도가 2018년인 조건2, 월이 1월인 조건3을 만든다.
→ 조건 3가지를 모두 만족하는 개수를 len함수를 사용하여 출력하면 6개이다.
# 풀이2
cond1 = df['country'] == "United Kingdom"
df['date_added'] = pd.to_datetime(df['date_added'])
cond2 = df['date_added'] >= '2018-1-1'
cond3 = df['date_added'] <= '2018-1-31'
print(len(df[cond1 & cond2 & cond3]))
실행 결과 :
6→ 'object'형인 'country' 컬럼을 pd.to_datetime() 함수를 사용해 변환해준다.
→ 조건을 부등호를 사용해 '2018-1-1' ~ '2018-1-31' 인 날짜를 만든다.
# 풀이3
cond1 = df['country'] == "United Kingdom"
df['date_added'] = pd.to_datetime(df['date_added'])
cond2 = df['date_added'].between('2018-1-1', '2018-1-31')
print(len(df[cond1 & cond2]))
실행 결과 : 6→ 'object'형인 'country' 컬럼을 pd.to_datetime() 함수를 사용해 변환해준다.
→ 조건을 between() 함수를를 사용해 '2018-1-1' ~ '2018-1-31' 인 날짜를 만든다.
# 풀이4
cond1 = df['country'] == "United Kingdom"
df['date_added'] = df['date_added'].fillna("")
str1 = "2018"
str2 = "January"
cond2 = df['date_added'].str.contains(str1)
cond3 = df['date_added'].str.contains(str2)
print(len(df[cond1 & cond2 & cond3]))
실행 결과 : 6→ 'object'형인 'country' 컬럼을 pd.to_datetime() 함수를 사용해 변환해준다.
→ 조건을 str.contains()함수를 사용해 '2018년'과 'January(1월)'이 포함된 날짜를 만든다.
추가 문제) 만약 'country'컬럼에 대소문자 함께 있고, 띄어쓰기가 있는 것도 있고 없는 것도 있다면?
# 띄어쓰기 제거
df['country'] = df['country'].str.replace(' ','')
# 소문자로 변경
df['country'] = df['country'].str.lower()
df['country']
cond1 = df['country'] == "unitedkingdom"
df['date_added'] = pd.to_datetime(df['date_added'])
df['year'] = df['date_added'].dt.year
df['month'] = df['date_added'].dt.month
cond2 = df['year'] == 2018
cond3 = df['month'] == 1
print(len(df[cond1 & cond2 & cond3]))
실행 결과 :
6→ 'country' 컬럼에 띄어쓰기가 있다면 str.replace(' ', '') 함수를 사용해 띄어쓰기를 제거 해준다.
→ 'country' 컬럼에 대소문자가 섞여있어 소문자로 변경하고 싶다면 str.lower() 함수를 사용하면 된다.
(소문자 -> 대문자 : str.upper() 함수 사용)
'빅데이터분석기사 > 작업형1' 카테고리의 다른 글
| [작업형1] 조건 / 평균 / bmi / 절대값 / 내림차순 구하기 (0) | 2023.06.24 |
|---|---|
| [작업형1] 평균 / 행(row)별 합 / 고유값 수 구하기 (0) | 2023.06.22 |
| [작업형1] 평균 / 그룹합 / datetime 변환 구하기 (0) | 2023.06.17 |
| [작업형1] 결측치 대체 / 사분위수 / 표준편차 구하기 (0) | 2023.06.17 |
| [작업형1] 결측치 대체 / 사분위수 구하기 (2) | 2023.06.17 |