
// 퇴근후딴짓 님의 강의를 참고하였습니다. //
Dataset :
1. 데이터 불러오기
import pandas as pd
df = pd.read_csv("members.csv")
df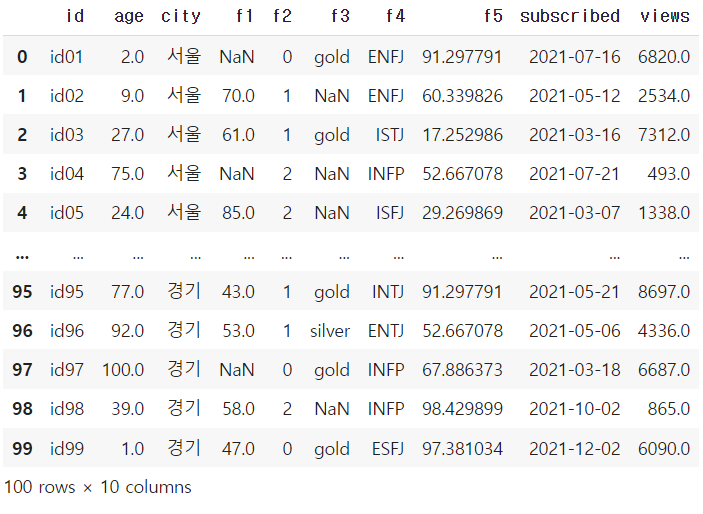
→ 100개의 행과 10개의 열로 이루어져있는 데이터셋이다.
문제1) 'views' 컬럼 상위 10개 데이터를 상위 10번째 값으로 대체한 후 'age'컬럼에서 80이상인 데이터의 'views'컬럼 평균값을 구하시오.
# views 컬럼 내림차순 정렬 후 상위 10개 불러오기
df = df.sort_values('views', ascending=False)
df.head(10)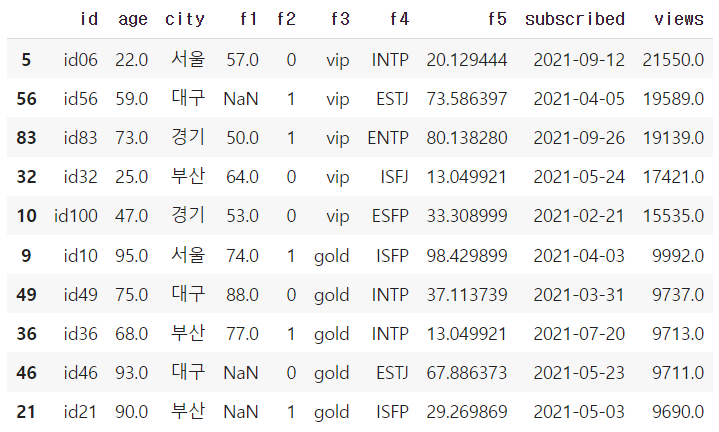
→ 상위 10개 데이터를 구하기 위해 내림차순(ascending=False)으로 정렬 후 10개의 데이터를 불러온다.
# 상위 10번째 값 구하기
min_value = df['views'][:10].min()
print(min_value)
min_value = df['views'].iloc[9]
print(min_value)
min_value = df['views'].head(10).min()
print(min_value)
실행 결과 :
9690.0
9690.0
9690.0→ slice 후 최소값 / iloc 10번째값 / head 후 최소값 3가지 방법으로 구할 수 있다. 결과는 모두 동일하다.
#10개 중에서 10번째 (최소값) 값 대체
df.iloc[:10,-1] = min_value→ .iloc를 사용해 모든 행, views 열의 값을 위에서 구한 최소값(min_value)로 대체한다.
# 대체된 데이터 확인
df.head(12)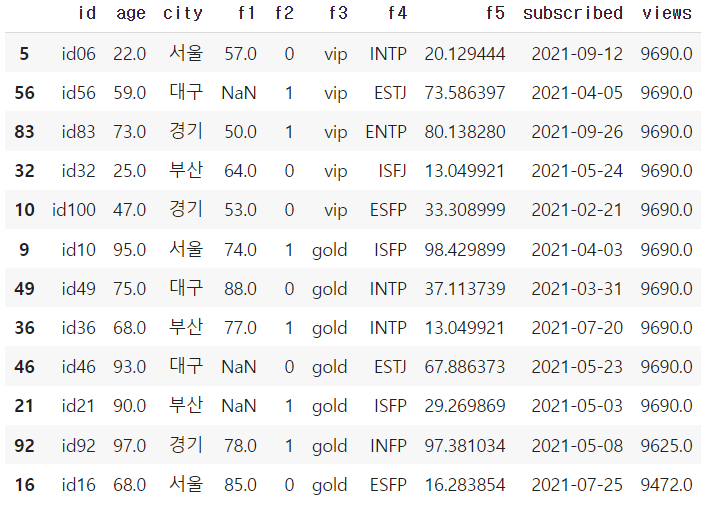
→ head(10)이 아닌 head(12)를 하여 10개값이 정상으로 대체되었는지와 10개 이후 값들이 그대로 인지 확인한다.
# age가 80 이상의 views 컬럼 평균
cond = df['age']>=80
print(df[cond]['views'].mean())
실행 결과 :
5674.04347826087→ 최종적으로 views 값을 대체 후 age >= 80 조건을 적용한 후의 views 컬럼 평균은 5674.04347826087이 나온다.
문제2) 주어진 데이터셋의 앞에서부터 순서대로 80% 데이터만 활용해 'f1'컬럼 결측치를 중앙값으로 채우기 전.후의 표준편차를 구하고, 두 표준편차 차이를 계산하시오. (단, 표본표준편차 기준, 두 표준편차 차이는 절대값으로 계산)
# 앞에서 부터 80% 데이터 뽑아오기
df = pd.read_csv("members.csv")
line = int(len(df) * 0.8)
line
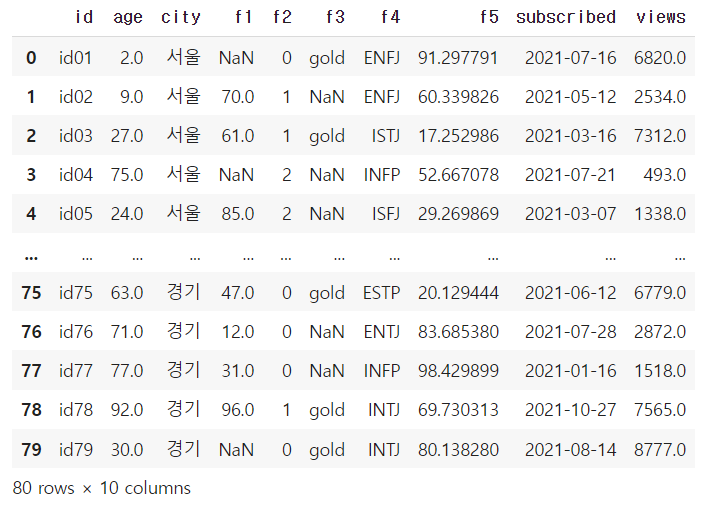
df = df.iloc[:line] # 0~79
df→ len(df)를 통해 전체 행의 개수(100개)를 구한 후 0.8을 곱하여 80% 데이터 수를 구하여 line 변수에 담는다.
→ 그 후 iloc에 line을 넣어 80개의 데이터로 df를 새로 만든다.
# 결측치 확인
df.isnull().sum()
실행 결과 :
id 0
age 0
city 0
f1 25
f2 0
f3 22
f4 0
f5 0
subscribed 0
views 3
dtype: int64→ f1 컬럼에 25개의 결측치가 있음을 알 수 있다.
# 결측치 채우기 전 f1컬럼 표준편자
std1 = df['f1'].std()
std1
실행 결과 :
20.574853076621935# f1 컬럼 중앙값 구하기
med=df['f1'].median()
med
실행 결과 :
68.0# f1 컬럼 결측치 중앙값으로 채우기
df['f1'] = df['f1'].fillna(med)# f1 컬럼 결측치 재확인
df.isnull().sum()
실행 결과 :
id 0
age 0
city 0
f1 0
f2 0
f3 22
f4 0
f5 0
subscribed 0
views 3
dtype: int64→ f1 컬럼의 결측치가 0개가 된 것을 확인 할 수 있다.
# 결측치를 채운 후 표준편차 구하기
std2 = df['f1'].std()
std2
실행 결과 :
17.010788646613275# 두 표준편차 차이 계산
print(abs(std1-std2))
실행 결과 :
3.56406443000866→ 최종적으로 f1 컬럼의 결측치를 채우기 전 표준편차와 결측치를 채운 후 표준편차의 차이는 3.56406443000866이다.
★심화학습★
- 모 표준편차(넘파이) vs 표본 표준편차(판다스)
import numpy as np
print(df['f1'].std())
print(np.std(df['f1']))
실행 결과 :
17.010788646613268
16.90413688272785→ 판다스로 구한 f1컬럼의 표준편차는 17, 넘파이로 구한 f1컬럼의 표준편차는 16.9이다.
→ 판다스는 표본 표준편차(n-1) / 넘파이는 모 표준편차(n)으로 구성되어있기 때문이다.
# 넘파이 모 표준편차 -> 표본 표준편차로 변경
print(df['f1'].std())
print(np.std(df['f1'], ddof=1))
실행 결과 :
17.010788646613268
17.010788646613268
# 판다스 표본 표준편차 -> 모 표준편차로 변경
print(df['f1'].std(ddof=0))
print(np.std(df['f1']))
실행 결과 :
17.010788646613268
17.010788646613268→ ddof=0 / ddof=1 설정으로 넘파이, 판다스의 표준편차를 변경해 같은 값으로 나오게 할 수 있다.
문제3) 주어진 데이터셋의 'age'컬럼의 이상치를 모두 더하시오. (평균으로부터 '표준편차 * 1.5)를 벗어나는 영역을 이상치라고 판단함)
# 표준편차, 평균값 구하기
df = pd.read_csv("members.csv")
std = df['age'].std() * 1.5
mean = df['age'].mean()
print("표준편차 * 1.5 : ", std)
print("평균 : ", mean)
실행 결과 :
표준편차 * 1.5 : 45.66413778388305
평균 : 50.963# 이상치 최저, 최고 기준 구하기
lower = mean - std
upper = mean + std
print("이상치 최저 기준 : ", lower)
print("이상치 최고 기준 : ", upper)
실행 결과 :
이상치 최저 기준 : 5.298862216116952
이상치 최고 기준 : 96.62713778388306# 이상치를 벗어나는 값(조건) 찾기
cond1 = df['age'] < lower
cond2 = df['age'] > upper
df[cond1]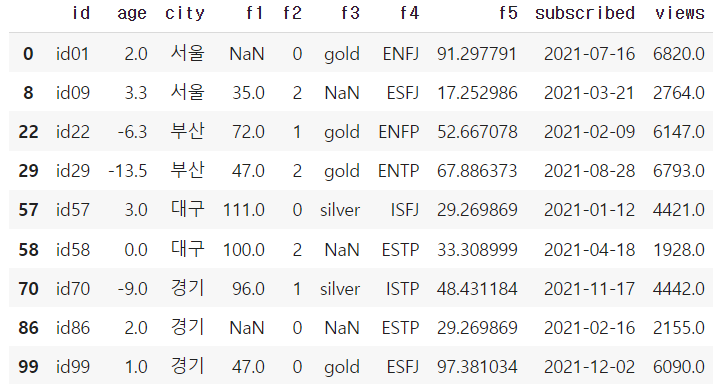
→ age 컬럼의 이상치 최저 기준보다 낮은 데이터이다.
df[cond2]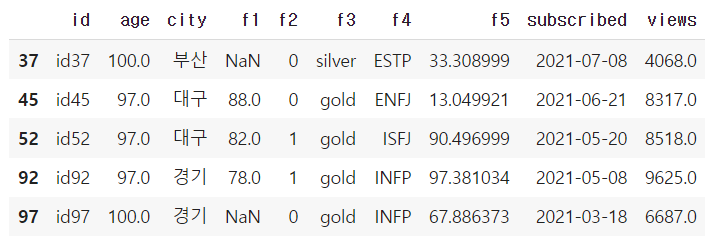
→ age 컬럼의 이상치 최고 기준보다 높은 데이터이다.
# 이상치 age 합하기
print(df[(cond1)|(cond2)]['age'].sum())
실행 결과 :
473.5→ 최종적으로 age 컬럼의 이상치를 합하면 473.5가 나온다.
'빅데이터분석기사 > 작업형1' 카테고리의 다른 글
| [작업형1] 평균 / 그룹합 / datetime 변환 구하기 (0) | 2023.06.17 |
|---|---|
| [작업형1] 결측치 대체 / 사분위수 / 표준편차 구하기 (0) | 2023.06.17 |
| [작업형1] 결측치 대체 / 사분위수 구하기 (2) | 2023.06.17 |
| [작업형1] 결측치 / 사분위수 / 데이터 수 구하기 (0) | 2023.06.17 |
| [작업형1] 레코드(row) 수 구하기 (0) | 2023.06.15 |