
1. YOLOv7이란
- YOLOv7은 객체 탐지 알고리즘 중 하나인 You Only Look Once (YOLO)의 버전 7이다.
- 실시간으로 탐지가 가능하고 속도가 빠르다.
- 다중 객체 탐지가 가능하다. 한 이미지에서 여러 객체를 동시에 탐지할 수 있다.
- 객체의 크기와 종횡비에 강인해 작은 객체나 다양한 크기의 객체도 정확히 탐지가 가능하다.
2. YOLOv7 설치
https://github.com/WongKinYiu/yolov7
- 먼저 github에 들어가 zip파일을 다운로드 받는다.
3. Jupyter Notebook
import os
os.getcwd()
실행 결과 :
'/storage01/shared_data/users/youngseok/YOLOv7'- 주피터 노트북에 다운로드 받은 YOLOv7을 업로드 한 후 os.getcwd()를 사용해
현재 경로를 찾는다.
import shutil
filename = './YOLOv7.zip' # 압축 해제할 파일
extract_dir = './YOLOv7/' # 압축 해제 시 폴더 이름
archive_format = 'zip'
shutil.unpack_archive(filename, extract_dir, archive_format)- 현재 경로를 찾은 후 위 코드에서 압축 해제할 zip파일과 압축 해제 시 폴더이름, format을
설정해주고 실행하면 YOLOv7 zip파일 해제가 된다.
!pip install -r requirements.txt- 위 코드를 실행해 필요한 라이브러리들을 한번에 설치한다.
import wget
wget.download('https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt')- 위 코드는 YOLOv7에서 필요한 가중치들을 다운로드 받는 코드이다.
!python train.py --device 6,7 --batch-size 16 --epochs 40 --img 640
--data ../data_monkey.yaml --weights yolov7.pt- YOLOv7에 있는 train.py 코드를 실행 시켜준다.
- device : 사용할 GPU 번호 (0부터 시작)
- batch-size : 한 번의 모델 업데이트에 사용되는 데이터의 수
-> 높을수록 메모리 사용량이 늘고 연산 시간이 길어진다.
- epochs : 전체 학습 데이터를 몇 번 반복할지
-> 높을수록 학습 결과가 좋아지지만 과적합 위험성 있음
- img : 이미지 크기
-> 클수록 학습 결과가 좋아질 수 있지만 연산 시간이 길어진다.
- data : yaml 파일 경로
- weights : 가중치
-> 다운로드 받은 yolov7.pt를 사용해준다.
train: ../object/monkey/monkey/train/images
val: ../object/monkey/monkey/valid/images
test: ../object/monkey/monkey/test/images
nc: 1
names: ['monkey']- yaml 파일이란 데이터의 구조와 계층을 표현하기 위해 들여쓰기를 사용하며,
주로 설정 파일이나 데이터 전송 형식으로 사용된다.
- train, val, test 폴더의 경로를 지정해준다.
- nc : class 개수
- names : class 명
- 이미지에서 원숭이 한 객체만 탐지하기 위해 개수는 1, class 명은 monkey로 설정해주었다.
- train, val, test 폴더에는 images, labels 두 폴더로 이루어져있다.
-> images 폴더에는 원숭이 이미지, labels 폴더에는 원숭이 이미지를 라벨링하고
난 후 좌표값 txt파일이 들어있다.
0 0.500000 0.485455 0.387978 0.890909- 라벨링 된 txt 파일 예시이다.
- 맨 앞 숫자 0은 각 클래스를 숫자로 지정해준다.
- 그 뒤로 나오는 숫자 4개는 객체의 경계 상자 정보이다.
- 일반적으로 (x_min, y_min, x_max, y_max) 형식으로 표현되며, 이는 경계 상자가 왼쪽 위
모서리의 (x_min, y_min) 좌표와 오른쪽 아래 모서리의 (x_max, y_max) 좌표로 정의된다.
- train.py 코드로 학습을 시키면 YOLOv7 -> runs -> train 폴더 순으로 들어가보면
exp1 ~ exp** 폴더가 생성된다.
- exp 폴더 안에 weights(가중치) / result.png / confusion_matrix.png / R_curve /
P_curve / PR_curve / F1_curve 등 모델 성능 평가 지표들이 있다.
- weights 폴더 안에 best.pt는 학습 중 가장 좋은 결과가 나온 가중치 정보가 저장되어 있다.
이는 뒤에 detect.py 코드 실행 시 사용된다.
!python detect.py --device 6,7 --weights runs/train/exp33/weights/best.pt
--conf 0.2 --img-size 640 --source ../object/monkey/monkey/test/images- train.py 코드로 학습이 끝난 후 detect.py 코드를 실행 시켜준다.
- device : 사용할 GPU 번호 (0부터 시작)
- weights : 가중치 경로 / exp는 학습할 때마다 생기므로 번호를 맞춰 써줘야한다.
-> 가장 좋은 결과가 나왔던 가중치 best.pt를 사용해준다.
- conf : 객체 탐지에 대한 신뢰도 임계값으로 0.2보다 높은 객체만 탐지 결과로 출력된다.
- img : 이미지의크기
- source : test할 이미지 폴더 경로
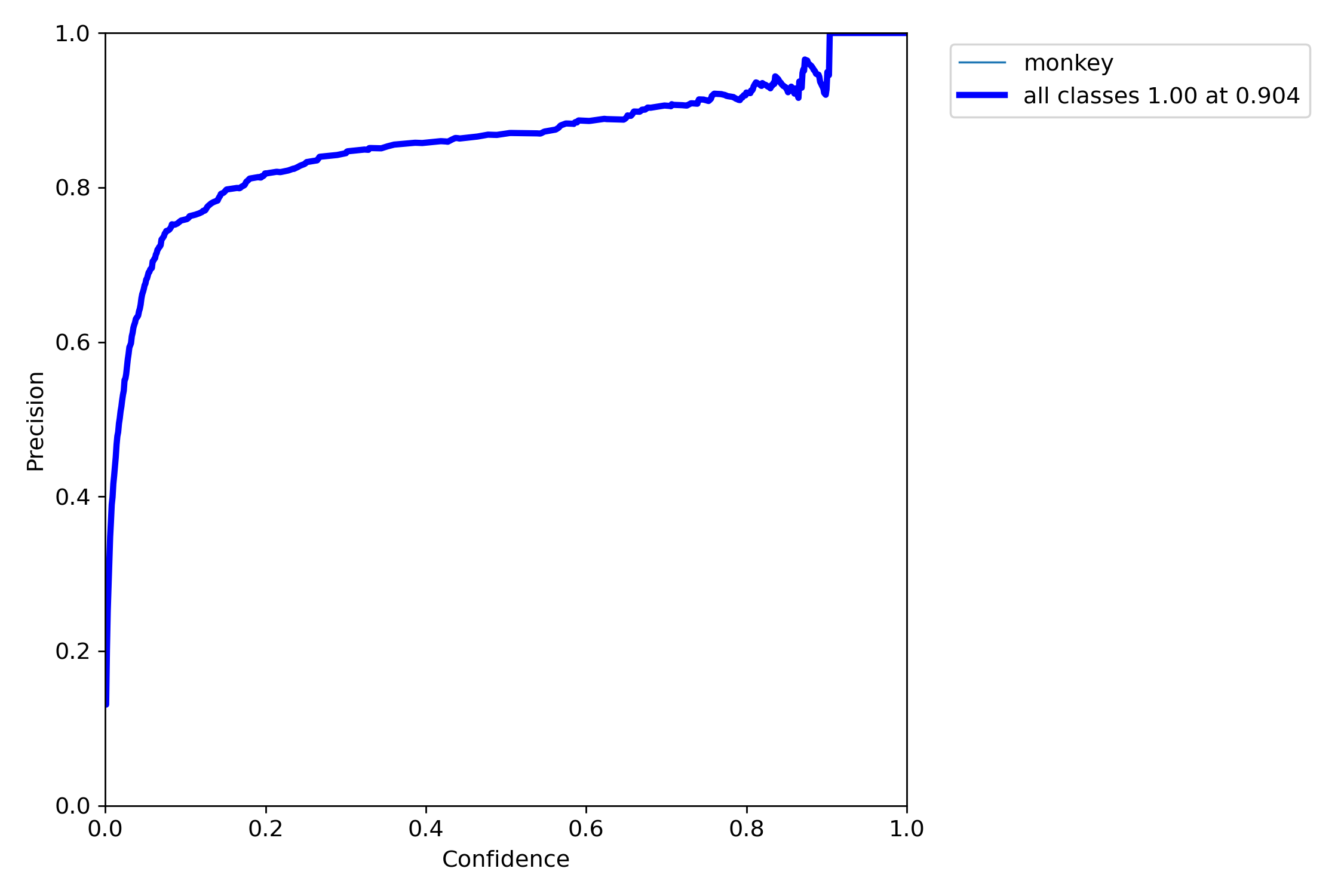
- P-curve 그래프를 시각화 한 것으로 0.904가 나왔다.
- 이는 모델이 양성으로 예측한 대상 중 실제로 90.4%가 양성이라는 의미이다.
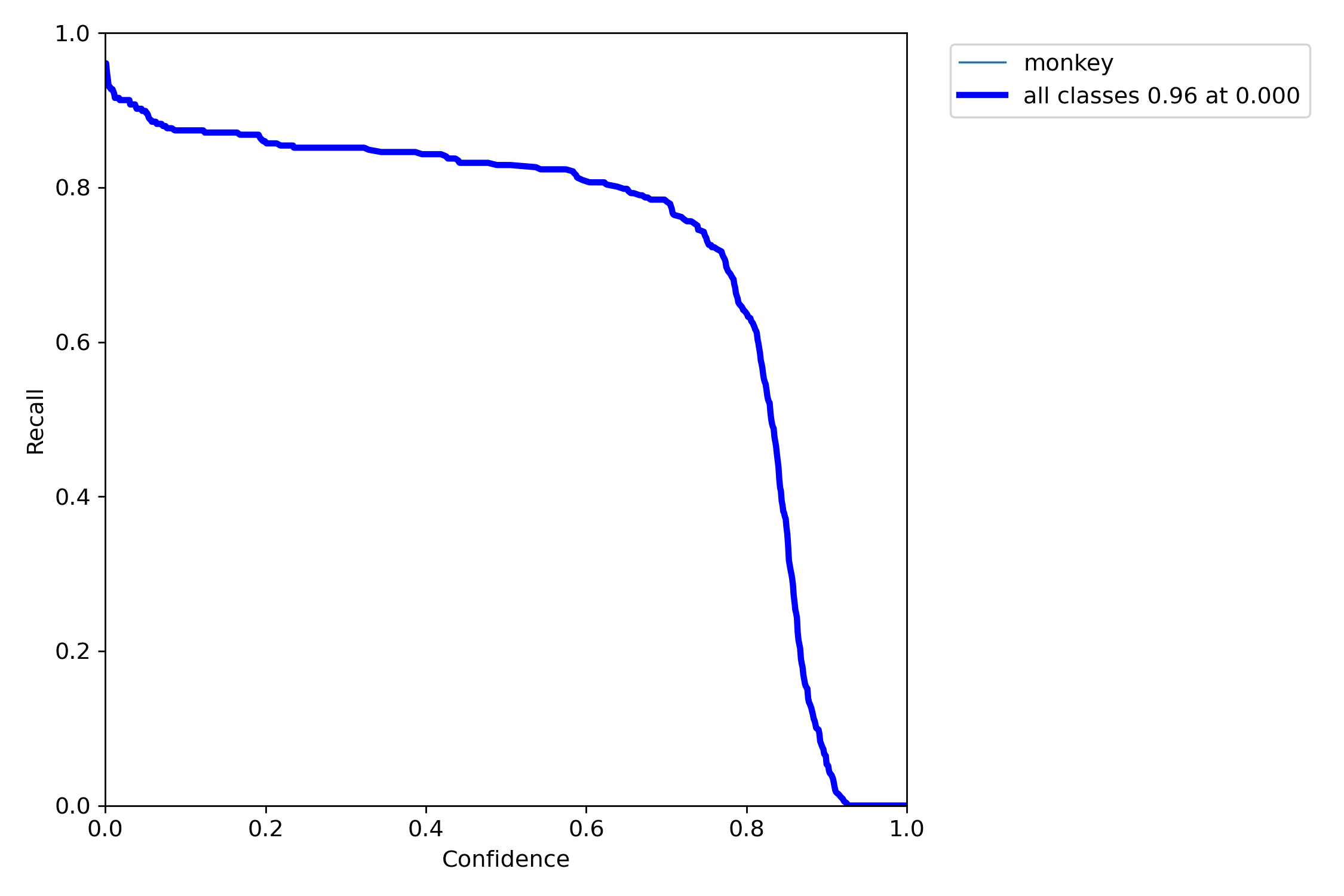
- R-curve 그래프를 시각화 한 것으로 0.96 나왔다.
- 이는 실제 양성인 대상을 예측한 확률이 96%라는 의미로 모델이 양성 샘플을
거의 다 찾았다고 볼 수 있다.
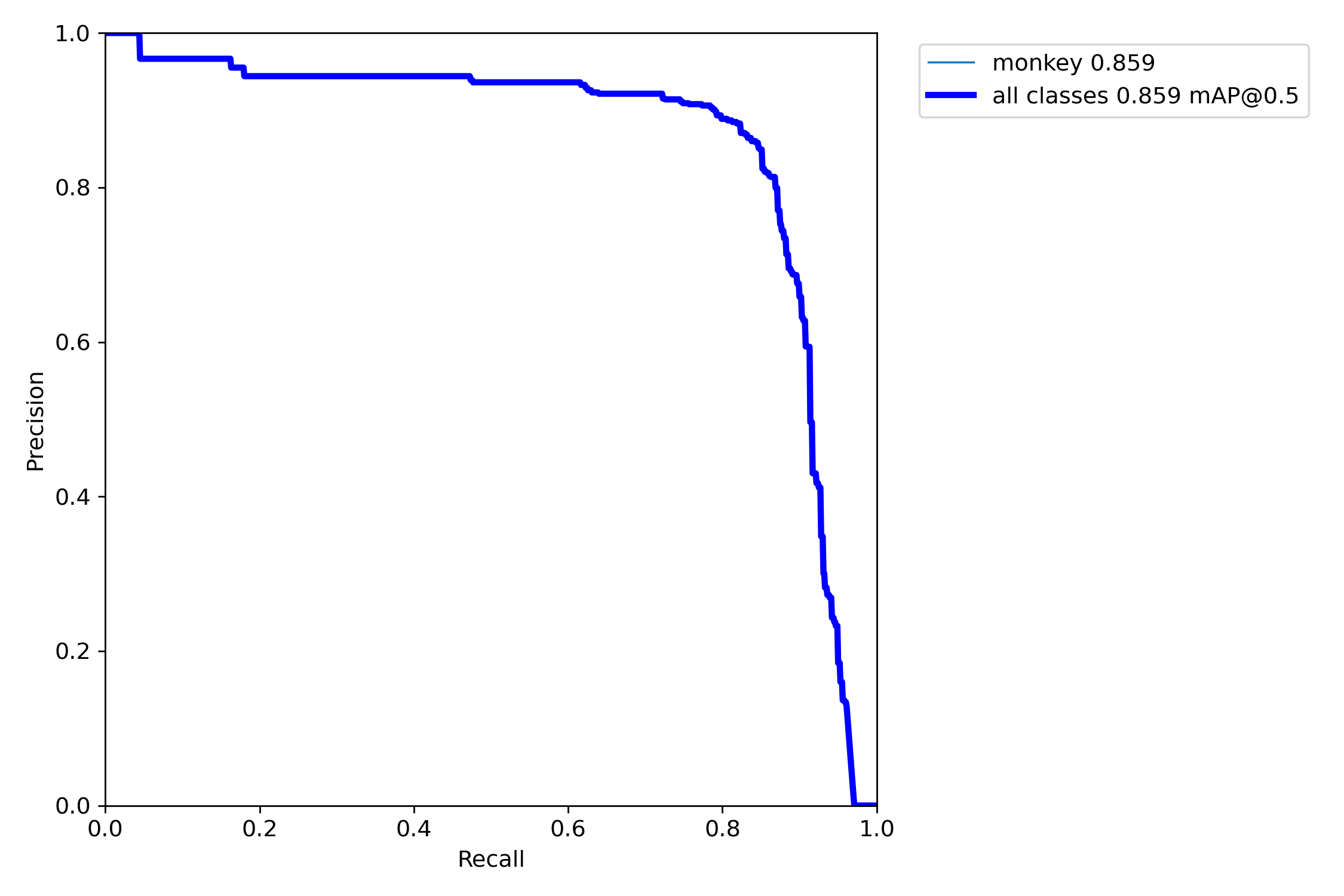
- PR-curve 그래프를 시각화 한 것으로 0.8590 나왔다.
- 정밀도와 재현율 사이의 조화 평균이 F1 Score를 나타내며, 모델의 전반적인 성능을 의미한다.

- 원숭이 이미지 학습 후 테스트 이미지를 넣었을때 원숭이 객체들을 잡아주는 것을 알 수 있다.
- 지금은 하나의 객체로 하였지만 한 이미지에서 여러 객체 탐지도 동시에 가능하다.
- 성능이 좋게 나온 결과로 작성하였지만 직접 해보면 성능이 잘 나오지 않는다.
- 이미지 분석을 하면서 성능을 높이기 위해 해본 방법들은 이미지 데이터 개수 추가,
고품질 이미지 사용, 일관성 있는 라벨링, epochs 늘리기 등이 있다.
- 이 중 고품질 이미지 사용과 많은 이미지 데이터 사용이 가장 효과가 좋았다.
'Python > 이미지 처리' 카테고리의 다른 글
| [Python] 이미지 데이터셋 수집 방법 3가지 (0) | 2023.07.10 |
|---|---|
| [Python] labelImg를 활용한 이미지 라벨링 (0) | 2023.07.10 |